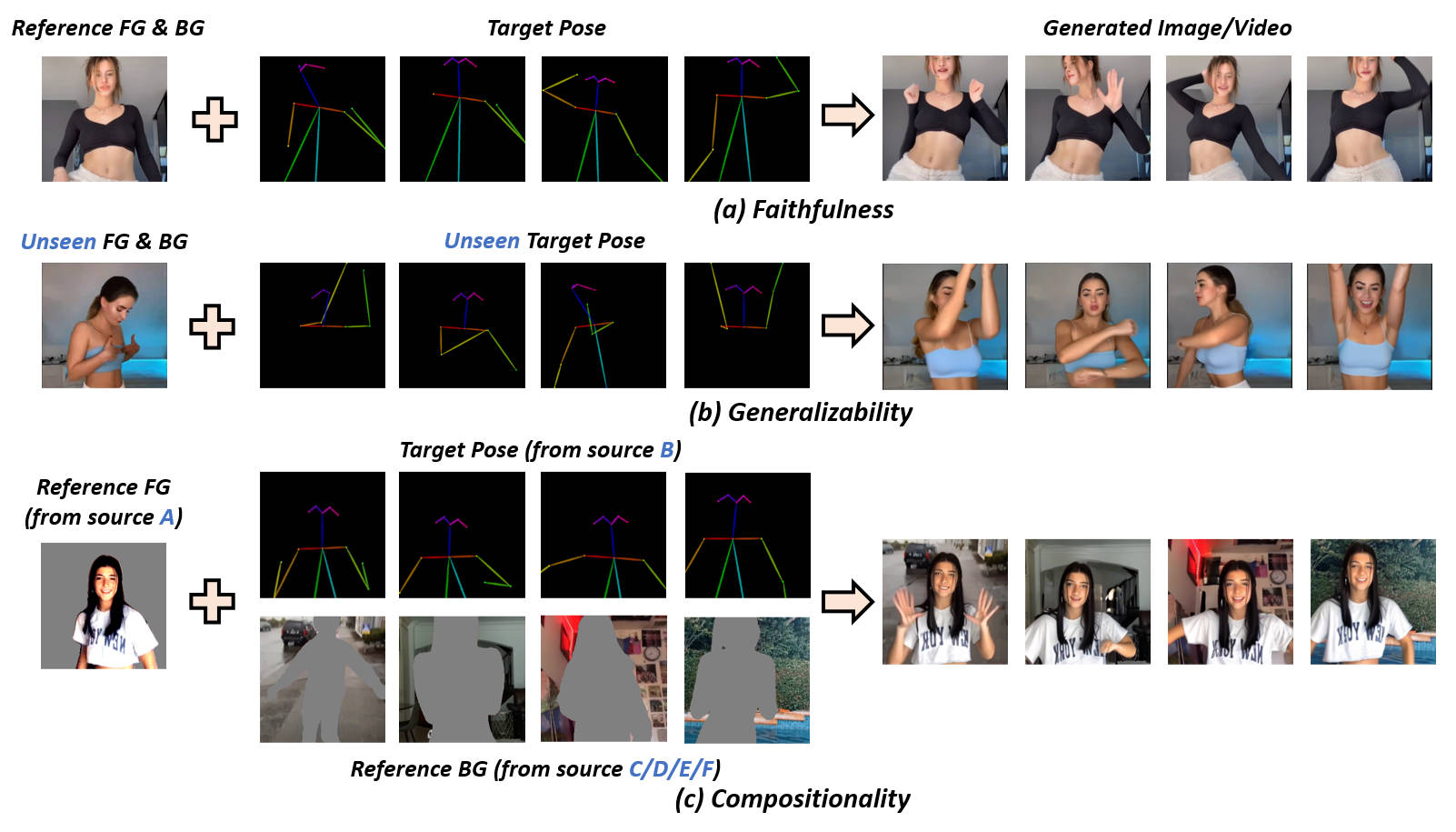
Generative AI has made significant strides in computer vision, particularly in image/video synthesis conditioned on text descriptions. Despite the advancements, it remains challenging especially in the generation of human-centric content such as dance synthesis. Existing dance synthesis methods struggle with the gap between synthesized content and real-world dance scenarios. In this paper, we define a new problem setting: Referring Human Dance Generation, which focuses on real-world dance scenarios with three important properties: (i) Faithfulness: the synthesis should retain the appearance of both human subject foreground and background from the reference image, and precisely follow the target pose; (ii) Generalizability: the model should generalize to unseen human subjects, backgrounds, and poses; (iii) Compositionality: it should allow for composition of seen/unseen subjects, backgrounds, and poses from different sources. To address these challenges, we introduce a novel approach, DisCo, which includes a novel model architecture with disentangled control to improve the faithfulness and compositionality of dance synthesis, and an effective human attribute pre-training for better generalizability to unseen humans. Extensive qualitative and quantitative results demonstrate that DisCo can generate high-quality human dance images and videos with diverse appearances and flexible motions..
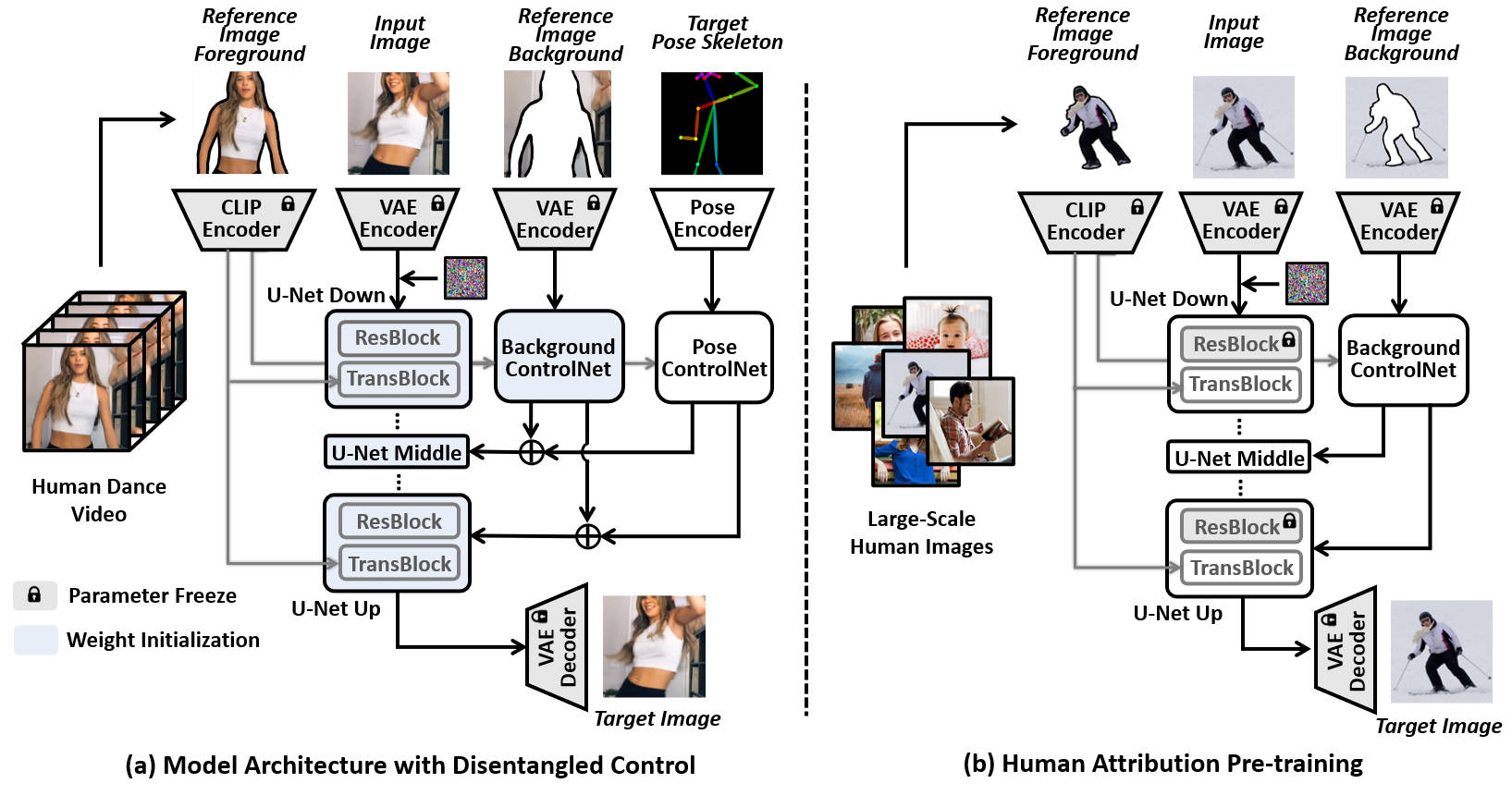
(a) Model Architecture with Disentangled Control: We propose an organic integration of conditions with cross-attention and ControlNet. Specifically, we substitute the text condition in T2I diffusion model with the CLIP image embeddings of the human subject, which is incorporated via the cross-attention modules of U-Net; while the background and human pose conditions are fed into two separate ControlNet branches. By disentangling the control from all three conditions, DisCo can not only achieve fidelity in human foregrounds and backgrounds but also enable arbitrary compositionality of human subjects, backgrounds, and dance-moves.
(b) Human Attribute Pre-training: We design a proxy task in which the model conditions on the separate foreground and background areas and must reconstruct the complete image. In this way, the model learns to better encode-and-decode the complicated human faces and clothes during pre-training, and leaves the pose control learning to the fine-tuning stage of human dance synthesis. Crucially, without the constraint of pairwise human images for pose control, we can leverage large-scale collections of human images to learn diverse human attributes, in turn, greatly improve the generalizability of DISCO to unseen humans.




 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
 |
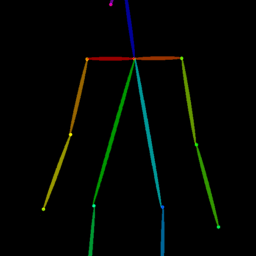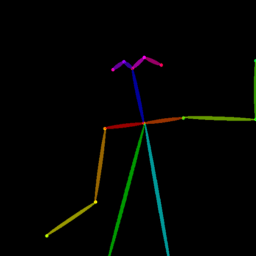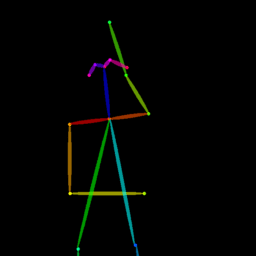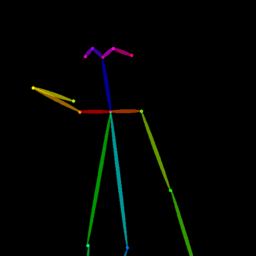
| Reference Img | Dance#1 | Dance#2 | Dance#3 | Dance#4 | Dance#5 |

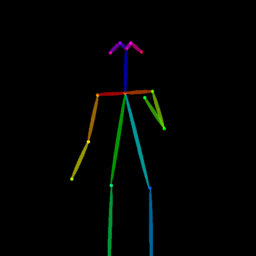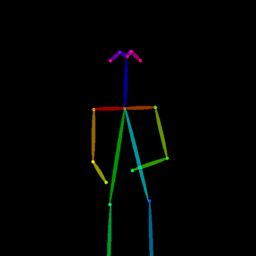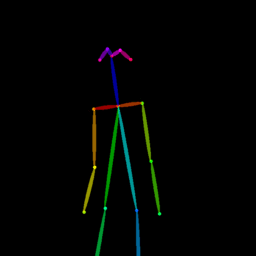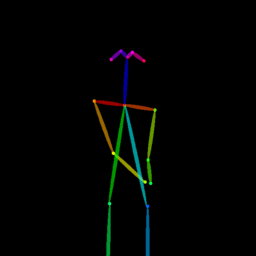 |
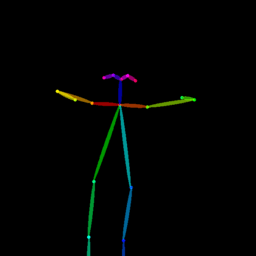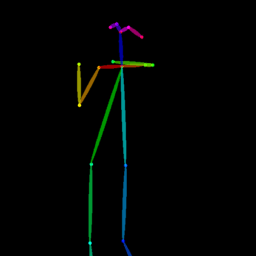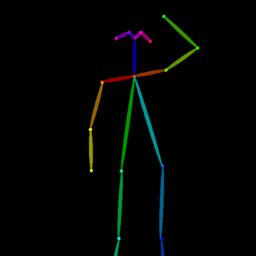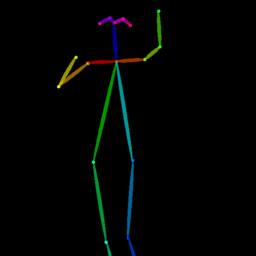 |
 |
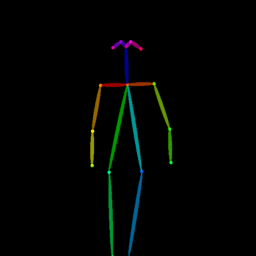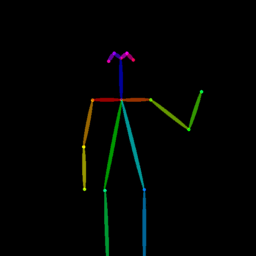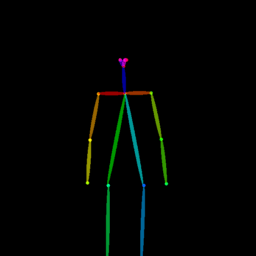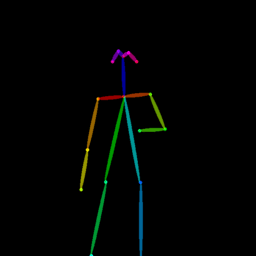 |
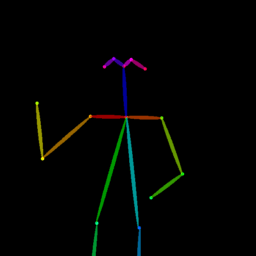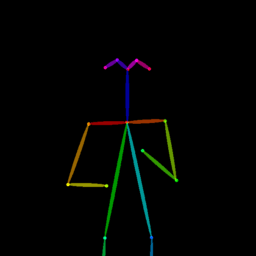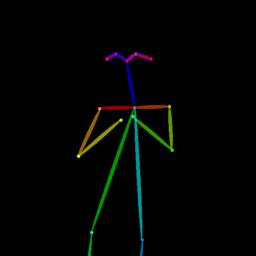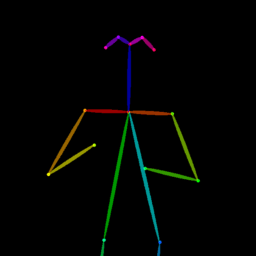 |
|
 |
 |
 |
 |
 |
 |
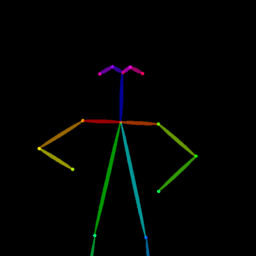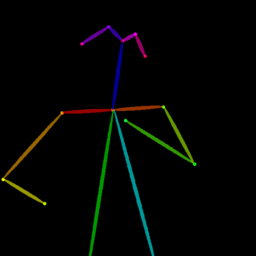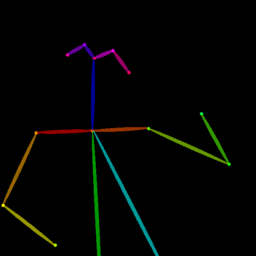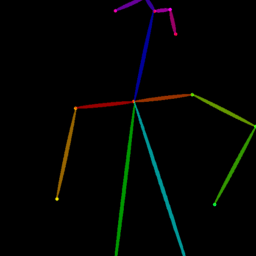
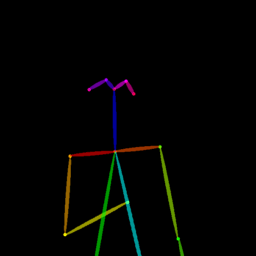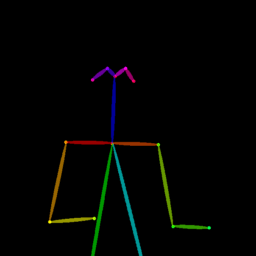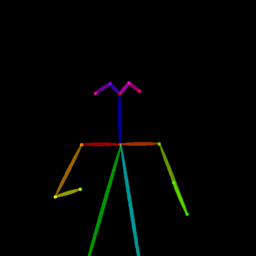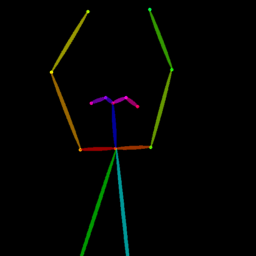
| Reference Img | Dance#1 | Dance#2 | Dance#3 | Dance#4 | Dance#5 |
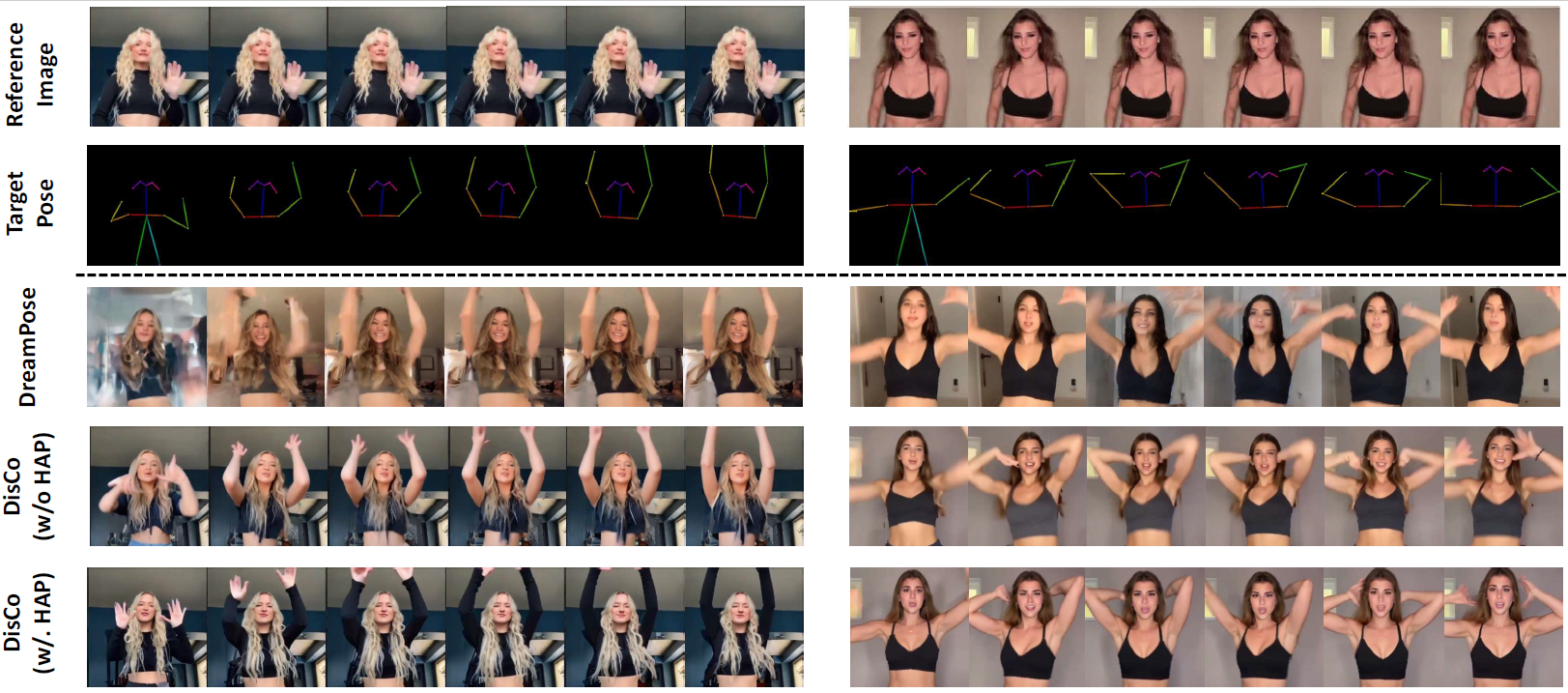
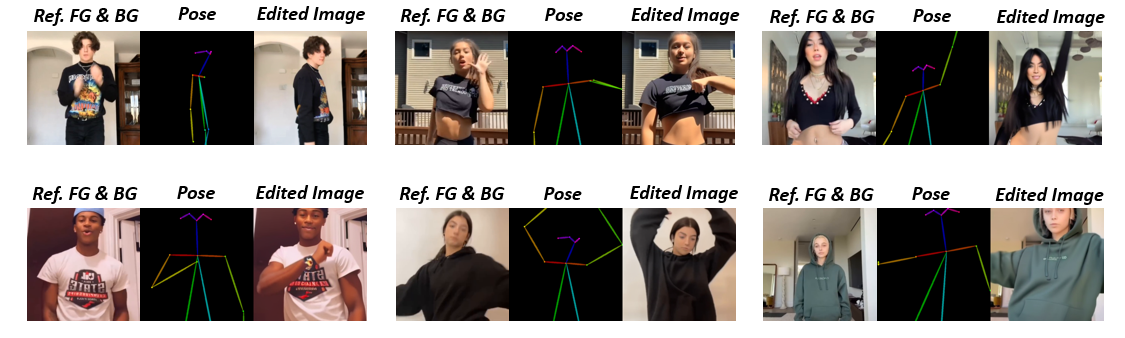
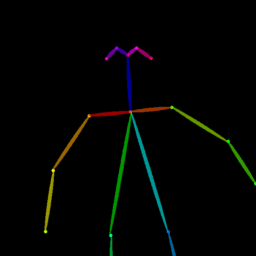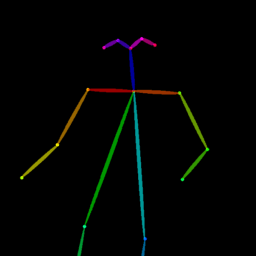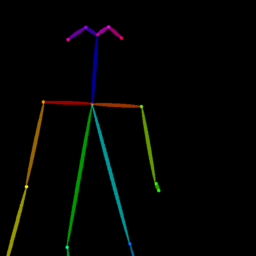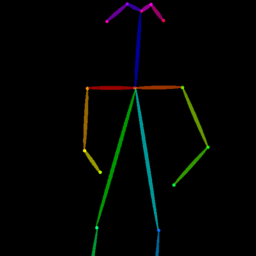
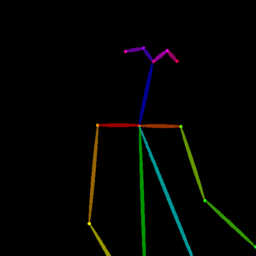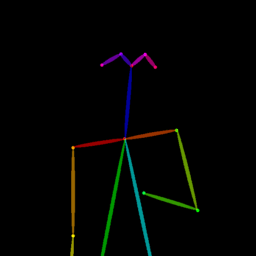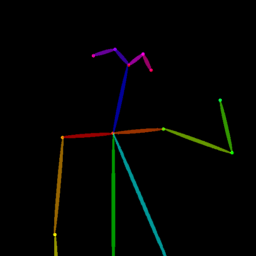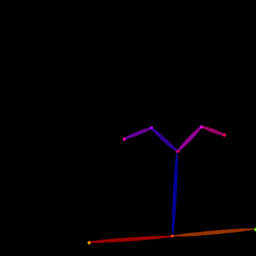
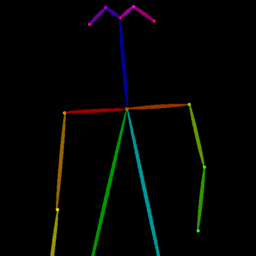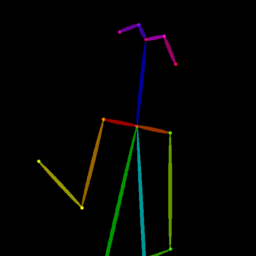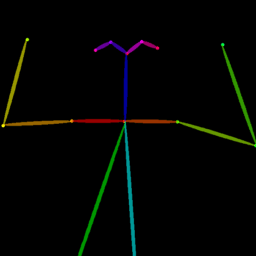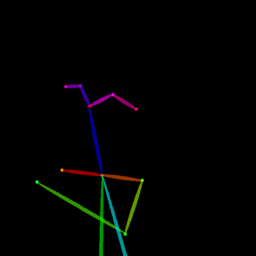
Qualitative comparison between our DISCO (w/ or w/o HAP) and DreamPose on referring human dance video generation with the input of a reference image and a sequence of target poses. Note that the reference image and target poses are from the testing split, where the human subjects, backgrounds, poses are not available during the model training.
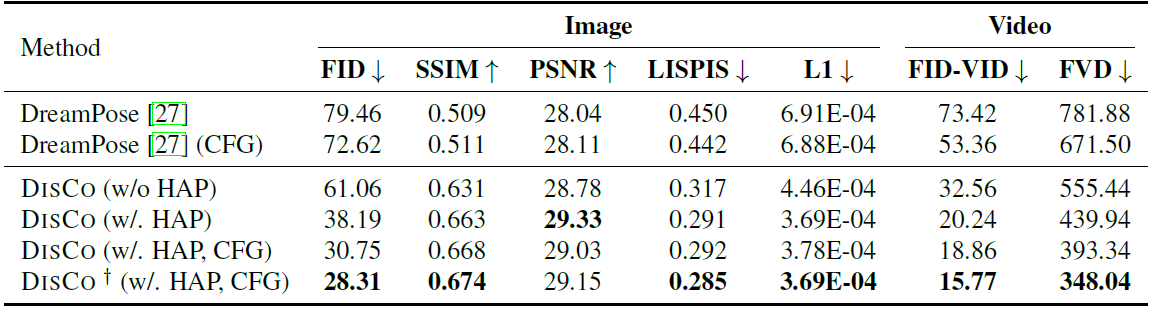
Quantitative comparisons of DISCO with the recent SOTA method DreamPose. “CFG” and “HAP” denote classifier-free guidance and human attribute pre-training, respectively. ↓ indicates the lower the better, and vice versa. For DISCO†, we further scale up the fine-tuning stage to ~600 TikTok-style videos.
If you use our work in your research, please cite:
@article{wang2023disco,
title={DisCo: Disentangled Control for Referring Human Dance Generation in Real World},
author={Wang, Tan and Li, Linjie and Lin, Kevin and Lin, Chung-Ching and Yang, Zhengyuan and Zhang, Hanwang and Liu, Zicheng and Wang, Lijuan},
journal={arXiv preprint arXiv:2307.00040},
website={https://disco-dance.github.io/},
year={2023}
}